2025. 1. 23. 13:00ㆍ프로젝트
이 전 글들이 궁금하다면 ?
0. 사이트를 만드려는 이유
https://hsjoo126.tistory.com/80
1-1. 프로젝트 가능성 보기
https://hsjoo126.tistory.com/81
pandas 와 jupyter 이용해서 테스트해보기
https://hsjoo126.tistory.com/82
1-2. 기획 단계 - 디자인, 와이어 프레임, ERD 등
https://hsjoo126.tistory.com/83
2. 개발 단계 - 계획짜기, 구현해보기
https://hsjoo126.tistory.com/84
2-1. 개발 단계 - 배당지불일, 시장별 티커리스트 구하기
https://hsjoo126.tistory.com/85
2-2. 개발 단계 - 코드 정리
https://hsjoo126.tistory.com/86
2-3. 개발 단계 - 사이트에 적용하기(장고)
https://hsjoo126.tistory.com/87
2-4. 개발 단계 - 사이트 로딩 속도 줄이기
https://hsjoo126.tistory.com/88
2-5. 개발 단계 - 주식별 동적인 페이지 만들기
https://hsjoo126.tistory.com/89
2-6. 개발 단계 - 티커리스트 db에 저장해서 불러오기, 해결하지 못한 트러블슈팅
https://hsjoo126.tistory.com/91
저번 글에서 429 오류를 맞이하고 ...
의욕을 잃은 채 하루가 지났다.
그리고 다시 코드를 돌려보는데 이런 에러가 떴다.
Error fetching data for CMCSA: ('Dividend Date', 0)
GPT 답변
Dividend Date 데이터가 없거나 누락됨: 일부 티커에는 배당 관련 정보가 없을 수 있습니다.
데이터 형식이 예상과 다름: Yahoo Finance에서 반환하는 데이터 형식이 변경되었거나 일관성이 없을 수 있습니다.
데이터 형식이 다를 수도 있다길래, GPT 랑 같이 오류 코드를 찍어보았다.
try:
# info가 dict 형식인 경우
if isinstance(info, dict):
dividend_date = info.get('Dividend Date', None)
# info가 DataFrame 형식인 경우
elif isinstance(info, pd.DataFrame) and not info.empty:
if 'Dividends' in info.index:
dividend_date = info.loc['Dividends', 0] # 값이 없으면 KeyError가 발생할 수 있음
except (KeyError, IndexError, TypeError) as e:
print(f"Error parsing Dividend Date for {ticker_symbol}: {e}")
그리고 코드를 다시 돌렸더니
error parsing Dividend Date for AAPL: 'builtin_function_or_method' object is not subscriptable이렇게 뜨긴했는데..
엄 ... 근데 별로 효과가 없는 거 같아서 타입을 명시하게끔 오류 코드를 바꿔주었다.
else:
print(f"[WARNING] Unexpected format for `calendar` in {ticker_symbol}: {type(info)}")
except (KeyError, IndexError, TypeError) as e:
print(f"Error parsing Dividend Date for {ticker_symbol}: {e}, Type of `info`: {type(info)}")
그리고 나서 이렇게 떴는데, 엄... 타입이 dict 라고 떴다.
Error parsing Dividend Date for NFLX: 'builtin_function_or_method' object is not subscriptable, Type of info: <class 'dict'>근데 왜 ? if문을 타지 않는 거지 ????
그러다가 .. 든 생각!
그냥! 데이터타입을 다 데이터프레임으로 바꾸고 돌리면 어떨까!!
데이터타입이 달라서 안 뜨는건지 그냥 데이터가 안뜨는건지 알 수 없으니까 ...
# 마지막 배당일
info = ticker_obj.calendar
dividend_date = None
try:
# `info`를 DataFrame으로 변환
df = pd.DataFrame(info)
# 'Dividend Date' 열이 있는 경우 첫 번째 값 추출
if 'Dividend Date' in df.columns:
dividend_date = df['Dividend Date'].iloc[0]
else:
print(f"No 'Dividend Date' for {ticker_symbol}, likely no dividends. Info: {df}")
dividend_date = "No Dividends"
except Exception as e:
print(f"Error parsing Dividend Date for {ticker_symbol}: {e}, Type of `info`: {type(info)}")이 코드를 적용하고! 성공했다~
그리고 또 에러문구에 뜨는 애들이 있었는데 그런 애들은
애초에 배당금을 지급하지 않는 기업이었다.
그런 애들은 calendar가 밑에 같은 형식으로 되어있었다!
Earnings Date Earnings High Earnings Low Earnings Average Revenue High Revenue Low Revenue Average
0 2025-01-30 0.9 0.59 0.75916 28928100000 25400000000 27168035690
이러니.. 배당일이 안 뜨지 .. ㅜ
아무튼, 배당일 관련, 예외처리도 다 해주고
이제! 어제 해결하지 못한 429에러를 해결할 차례이다.
저번 글에서 429에러를 만나면서...
티커의 갯수를 줄여 조회해봐도 조회가 되지 않는 현상이 나타났었다.
내가 너무 많은 데이터를 요청하니까 아예 내 요청을 막아버린 듯한 느낌이었는데,
오늘이 되서 100개씩 요청을 해보니 되긴 했다.
지금 해볼 것은
1. 데이터를 100개씩 나눠서 요청한다.
2. 요청 사이에 시간을 둔다.
이 두가지를 코드에 넣어서 짜볼 것이다.
이렇게 해서 코드를 짰는데
100개씩 불러오게 하고 5초 쉬고 다시 100개씩 불러오는 코드다
def middle(request):
# Redis에서 데이터 가져오기
cache_key = "stock_data_4_to_7"
stock_data = cache.get(cache_key)
# Redis에 데이터가 없을 경우, 실시간으로 데이터 수집
if not stock_data:
tickers = list(Ticker.objects.all())
stock_data = []
# 티커 리스트를 100개씩 나누기
batch_size = 100
for start in range(0, len(tickers), batch_size):
batch = tickers[start:start + batch_size]
for ticker in batch:
try:
ticker_symbol = ticker.symbol
ticker_obj = yf.Ticker(ticker_symbol)
# 데이터 수집
current_price = ticker_obj.info.get('currentPrice', '정보없음')
dividends = ticker_obj.dividends
last_dividend_value = dividends.iloc[-1] if not dividends.empty else None
# 마지막 배당일
info = ticker_obj.calendar
dividend_date = None
try:
# `info`를 DataFrame으로 변환
df = pd.DataFrame(info)
# 'Dividend Date' 열이 있는 경우 첫 번째 값 추출
if 'Dividend Date' in df.columns:
dividend_date = df['Dividend Date'].iloc[0]
else:
# print(f"No 'Dividend Date' for {ticker_symbol}, likely no dividends. Info: {df}")
dividend_date = "No Dividends"
except Exception as e:
print(f"Error parsing Dividend Date for {ticker_symbol}: {e}, Type of `info`: {type(info)}")
yield_value = ticker_obj.info.get('dividendYield', 0) * 100
market_cap = ticker_obj.info.get('marketCap')
# 4~7% 배당률 필터링
if 4 <= yield_value <= 7:
stock_data.append({
'ticker': ticker_symbol,
'current_price': current_price,
'last_dividend': last_dividend_value,
'dividend_date': dividend_date,
'dividend_yield': round(yield_value, 2),
'market_cap': "{:,}".format(market_cap) if market_cap else None,
})
except Exception as e:
print(f"Error fetching data for {ticker_symbol}: {e}")
# API 요청 간 시간 간격 추가 (선택적)
time.sleep(5) # 5초 대기
# Redis에 데이터 저장
cache.set(cache_key, stock_data)
print(f"완료했습니다. 총 티커 갯수: {len(tickers)}")
티커 갯수가 약 6300개이고....
100개당 2분 정도가 걸리고,, 거기다가 5초 대기했다가 하라고 했으니까?
엄... 131분 정도가 걸린다 이게 맞나..
약 30분 정도 돌린 후 맞이한 오류 파티 ..
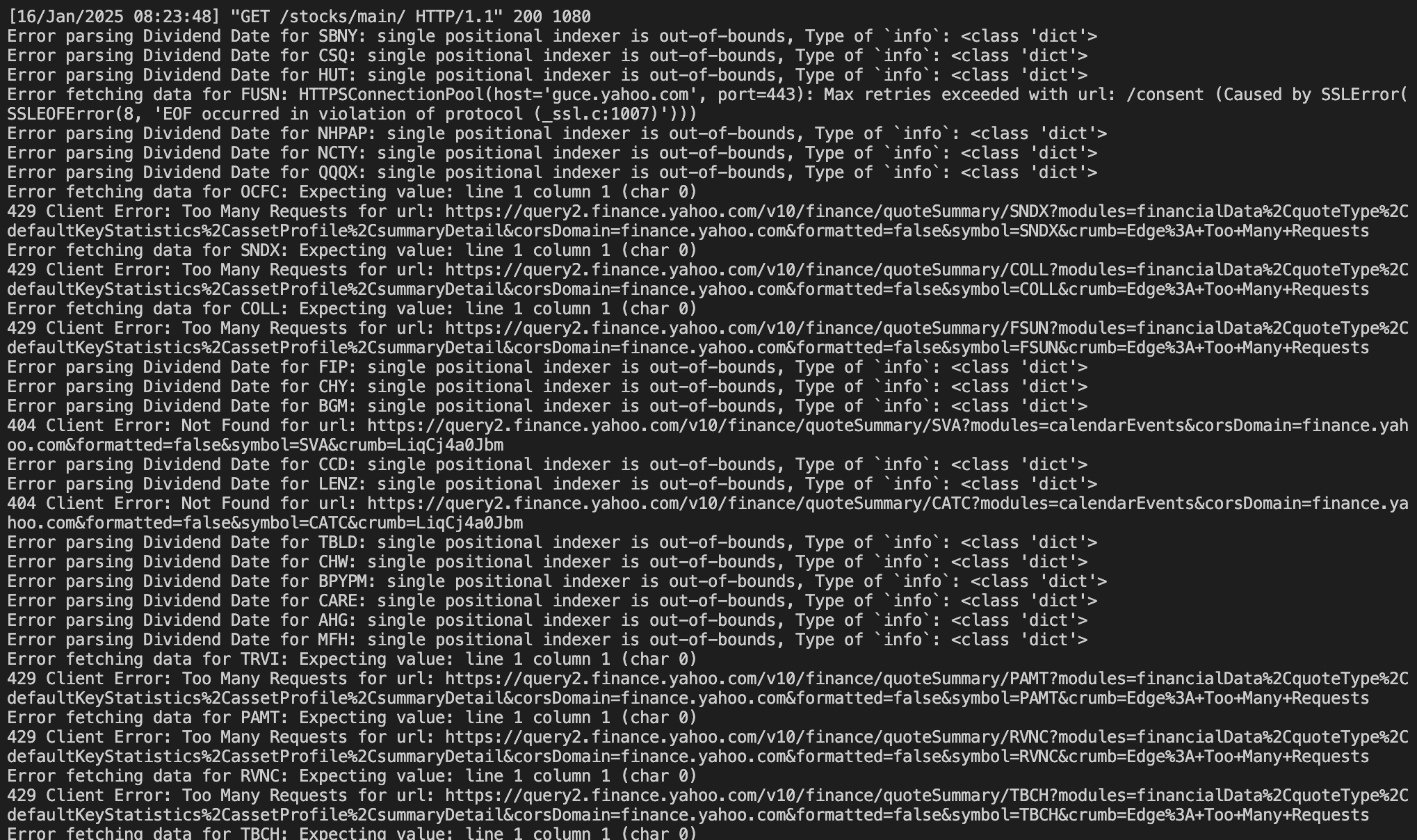
결국엔 내가 요청하는 데이터를 줄여야 해결이 되는 문제같다.
지금 드는 생각으로는 이런 방법으로 해결할 수 있을 거 같다.
1. 배당금이 없는 주식은 미리 거른다.
2. 나스닥과 뉴욕 증권 거래소를 나눠서 페이지 제공을 한다.
3. 병렬 처리를 한다.(멀티쓰레딩/멀티프로세싱) ->GPT추천!
음. 1번은 가능은 하지만 어쨌든 똑같이 N개의 데이터 요청을 보내야한다.
그럼... 똑같이 429에러뜰 거 같다. (젠장
2번 같은 경우 현재는 나스닥과 뉴욕 증권 거래소의 티커들이 한 번에 db에 들어가있는데
이걸 나누면 과부하를 줄일 수 있지 않을까 싶어서 넣어놓은 건데?
나눠도,,,,,, 데이터가 약 3천개여서 ... 허허허허허허ㅓ소용이 없을 거 같다.
3번은 한 번도 안 해봤고 ... 잘 모르는데 ,,, 일단 공부를 해봐야 알거 같다.
결론은 ...
몇천개의 데이터를 요청하는 건 변함이 없다.
429 에러가 안 뜨려면 ... 데이터를 나눠서 하든지 아니면 내 시간을 .. 다 쏟아야한다!
아니면! 돈 내고 유료 api 쓰기~ 하하하하
크론탭까지 돌릴 수 있으려면 최소 5분 이내로 데이터 요청 응답이 완료 되어야한다.
(2시간 걸리는 작업을 크론탭한테 시켜봤자..)
3번을 시도하는 과정에서
내가 잘 모르고, 병렬처리하는 게 시간을 크게 단축해주지 않겠다라는 생각이 들었다.
여러번 시도해봤는데 ... 잘 안 되서 하하하하
정말정말 생각을 오랫동안 해봤는데,
뭐하나 포기를 해야할 거 같다.
로직 대폭 개선하기
현재 우리 사이트에는 총 4개의 페이지가 있다.
1. 메인페이지
2. 배당률이 4-7%인 주식 모아놓은 페이지(middle)
3. 배당률이 7%이상 주식 모아놓은 페이지(high)
4. 개별 주식 페이지
1번을 제외한 나머지 3개의 페이지는 다 실시간으로 로딩이된다.
(crontab이 데이터를 불러다가 redis에 저장 -> view에서 redis 데이터를 불러다가 보여줌)
4. 개별 주식 페이지는 데이터를 한 개만 조회하는 거니까 잘 로딩되는데.
2,3번 페이지들은 굉장히 오래걸릴 뿐더러 야후 파이낸스에서 요청을 아예 막아버렸다.
그래서 내가 생각한 방법은 바로 실시간 로딩을 포기 하는 거다.
어차피 배당금은 실시간으로 변동되지 않는다. 그리고 잘 굴러가게하려면 유료 API 를 사용해야한다 ... ㅠ
하루에 한 번이나 이틀에 한 번씩 업데이트 하는 방식을 사용하면 좋을 거 같다.
정리
크론탭을 사용해서 배당률 페이지 데이터를 DB에 저장한다.
배당률 페이지는 DB를 조회를 통해 사이트를 보여준다.
하루에 한 번씩 크론탭은 DB를 업데이트 한다.
생각한 로직을 실천해보기 위해
내가 해야할 일들을 적어보겠다.
1. 모델 하나 새로 만들기.
2. 배당금있는 주식만 걸러내기
3. 걸러낸 주식을 기반으로 cron.py돌려서 데이터 수집하고 redis와 DB에 저장하기
4. view로직 수정하기(만약, redis에 데이터가 없다면 db조회해서 가져올 수 있도록)
모델 간단하게 만들고!
class DividendTicker(models.Model):
symbol = models.CharField(max_length=10, unique=True) # 티커 심볼
market = models.CharField(max_length=100, null=True, blank=True) # 시장
checked_at = models.DateTimeField(auto_now_add=True) # 확인 날짜
def __str__(self):
return self.symbol
기존 모델에 있던 티커들을 조회해서 배당금이 있는지 없는지 조회하는 로직을 짰다.
def check_and_filter_dividends():
# Ticker 테이블에서 모든 티커 가져오기
tickers = Ticker.objects.all()
dividend_tickers = []
# 100개씩 분할하여 처리
batch_size = 100
for i in range(0, len(tickers), batch_size):
batch = tickers[i:i + batch_size]
for ticker in batch:
try:
# yfinance를 사용해 티커 데이터 가져오기
stock = yf.Ticker(ticker.symbol)
# dividends 확인
dividends = stock.dividends
if not dividends.empty: # dividends가 비어있지 않으면
dividend_tickers.append(DividendTicker(
symbol=ticker.symbol,
market=ticker.market
))
except Exception as e:
print(f"Error processing {ticker.symbol}: {e}")
#테이블에 저장
DividendTicker.objects.bulk_create(dividend_tickers, ignore_conflicts=True)
dividend_tickers = [] # 다음 배치를 위해 리스트 초기화
# 10초 대기
print(f"Processed {i + batch_size} tickers. Waiting for 10 seconds...")
sleep(10)
print("Task completed!")한 번에 요청했다가 또 ^^ 429 에러가 뜰 수 있기 때문에,
한 바퀴 돌 때마다 10초간 쉬라는 것도 덧붙여줬다!
함수를 다 작성하고 난 이후에는 쉘에서 작동해줬다.
#터미널에 한 줄씩 작성하고 엔터치기!
python manage.py shell
from 앱이름.cron import check_and_filter_dividends
check_and_filter_dividends()
오 그래도! 배당률 페이지보단 훠어어얼씬 빠르게 되고 있다!!! 다행이야 엉엉 ㅠㅠ
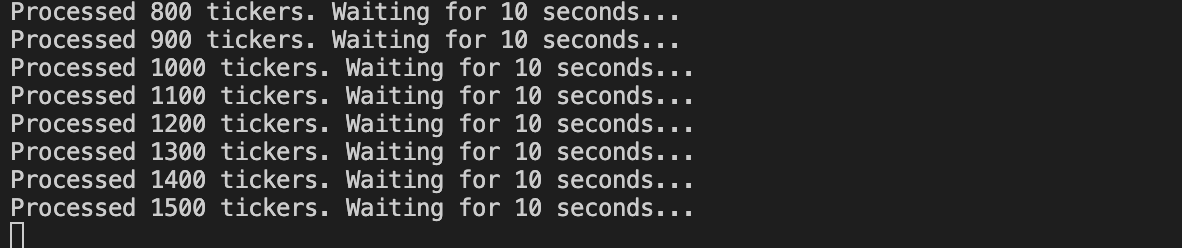
시간을 재보니 100개당 약 30-40초 정도 걸리는 거 같다!! 다행이야 ㅠㅠ
...
아니야 ... 안 다행이야 .. 언제 끝나..?
....
돌아가는 게 다행이라고 해야할지 ... 허허허허허
이제야 5900개임... 살려줘 ...
... 휴 끝났다!
이걸 돌리면서 ticker의 이름은 바뀌되, 같은 오류가 떴는데
다음 3가지 이다.
SFB: Period 'max' is invalid, must be one of ['1d', '5d']
$WRB PR E: possibly delisted; no timezone found
$MTR: possibly delisted; no price data found (1d 1926-02-11 -> 2025-01-17)
근데 이건 yf에서 불러올 수 없기 때문에 ... 이런 오류가 뜬 거라 내가 해결할 수 있는게 없고
gpt한테도 물어봤는데 오류에 대한 예외처리는 할 수 있으나 yf에서 불러올 수 있는 방법은 없다고 했다
데이터는 거의 절반으로 줄어들었다!
이제 이걸 가지고 데이터를 수집해보겠다.
먼저 데이터 수집 후 저장할 모델을 정의해야한다.
class CollectedDividendData(models.Model):
ticker = models.CharField(max_length=10, unique=True) # 티커 심볼
current_price = models.FloatField(null=True, blank=True) # 현재 주가
last_dividend = models.FloatField(null=True, blank=True) # 마지막 배당금
dividend_date = models.CharField(max_length=100, null=True, blank=True) # 배당일
dividend_yield = models.FloatField(null=True, blank=True) # 배당률
market_cap = models.CharField(max_length=50, null=True, blank=True) # 시가총액
dividend_yield_category = models.CharField(
max_length=20, choices=[("4_to_7", "4~7%"), ("above_7", "7% 이상")], null=True
) # 배당률 범주
def __str__(self):
return f"{self.ticker} - {self.dividend_yield_category}"gpt가 짜줬다 ㅋㅋㅋㅋㅋ
그리고 DB에 넣을 데이터 수집할 코드를 작성해주고!
import time
import pandas as pd
import yfinance as yf
from .models import DividendTicker, CollectedDividendData
from django.core.cache import cache # Redis 캐시 사용을 위한 import
def update_dividend_data():
tickers = DividendTicker.objects.all() # DividendTicker에서 티커 가져오기
batch_size = 100 # 한 번에 처리할 티커 개수
# 티커 배치별 처리
for i in range(0, len(tickers), batch_size):
batch = tickers[i:i + batch_size] # 100개씩 배치 처리
# 배치 내 티커 처리
for ticker_obj in batch:
ticker_symbol = ticker_obj.symbol
try:
ticker_data = yf.Ticker(ticker_symbol)
# 종가 가져오기 (최근 1일 기준)
data = ticker_data.history(period="1d")
close_price = data['Close'].iloc[-1] if not data.empty else None # 종가가 없으면 None
# 배당금 정보
dividends = ticker_data.dividends
last_dividend = dividends.iloc[-1] if not dividends.empty else None
# 배당일 처리 (calendar에서 'Dividend Date'를 추출)
calendar = ticker_data.calendar
dividend_date = None
try:
# calendar가 dict인 경우에 'Dividend Date' 키 확인
if isinstance(calendar, dict) and 'Dividend Date' in calendar:
dividend_date = calendar['Dividend Date']
else:
print(f"No 'Dividend Date' for {ticker_symbol}, likely no dividends.")
dividend_date = "No Dividends"
except Exception as e:
print(f"Error parsing Dividend Date for {ticker_symbol}: {e}, Type of calendar: {type(calendar)}")
# 배당률과 시가총액
dividend_yield = ticker_data.info.get('dividendYield', 0) * 100
market_cap = ticker_data.info.get('marketCap')
# 저장할 데이터 생성
dividend_yield_category = None
if 4 <= dividend_yield <= 7:
dividend_yield_category = "4_to_7"
elif dividend_yield > 7:
dividend_yield_category = "above_7"
# CollectedDividendData에 데이터 저장
if dividend_yield_category:
CollectedDividendData.objects.update_or_create(
ticker=ticker_symbol,
defaults={
"current_price": close_price, # 종가 사용
"last_dividend": last_dividend,
"dividend_date": dividend_date,
"dividend_yield": round(dividend_yield, 2),
"market_cap": "{:,}".format(market_cap) if market_cap else None,
"dividend_yield_category": dividend_yield_category,
},
)
except Exception as e:
print(f"Error fetching data for {ticker_symbol}: {e}")
# 각 배치마다 10초 대기 후, 처리된 티커 수 출력
print(f"Processed {i + batch_size} tickers. Waiting for 10 seconds...")
time.sleep(10)
print("배당률 데이터가 성공적으로 업데이트되었습니다!")
기존 코드와 수정된 부분이 있다면 현재 주가를 불러오는 코드가 그 전 날 종가를 불러오는 코드로 변경했고
dividend_date 는 calendar형태가 다 dict로 되어있길래, 데이터 프레임 형식은 빼버리고 dict 코드만 남겨놓았다.
그리고 코드를 돌려보았당
#한 줄씩 입력
python manage.py shell
from 앱이름.cron import update_dividend_data
update_dividend_data()
그런데 .... last_dividend 데이터가 다 NULL로 뜨는 거다 ...
진짜 .......... 하.. 나 제대로 썼잖아 나한테 왜그러냐 진짜 ..
근데? 따로 이런식으로 코드작성해서 돌리면
#배당금
ticker = yf.Ticker("SNY")
dividends = ticker.dividends
if not dividends.empty:
last_dividend_value = dividends.iloc[-1]
print(f"마지막 배당금 금액: {last_dividend_value}")
else:
print("배당금 데이터가 없습니다.")잘 나옴 ㅋㅎㅋㅎ
젠장 ㅋㅋㅋㅋㅋㅋㅋㅋㅋ
이리저리 코드 바꿔보고 ..
전체 코드 다시 한 번 더 돌려봤는데
똑같았다 ..
(코드 한 번씩 돌리는데 40분정도 소요되는데 엉엉.....)
그러다가 그냥 ... ㅋㅋㅋㅋ ㅜㅜ
last_dividend 항목만 다시 뽑아내는 코드를 짰다...
import yfinance as yf
from .models import CollectedDividendData
def update_last_dividend():
# CollectedDividendData에서 모든 주식 가져오기
stocks = CollectedDividendData.objects.all()
# 주식별로 처리
for stock in stocks:
ticker_symbol = stock.ticker # CollectedDividendData의 ticker 필드 사용
try:
# Yahoo Finance에서 데이터 가져오기
ticker_data = yf.Ticker(ticker_symbol)
dividends = ticker_data.dividends
# 마지막 배당금 확인
last_dividend = dividends.iloc[-1] if not dividends.empty else None
# CollectedDividendData의 last_dividend 필드 업데이트
if last_dividend is not None:
stock.last_dividend = last_dividend
stock.save() # 변경 내용 저장
print(f"Updated last_dividend for {ticker_symbol}: {last_dividend}")
else:
print(f"No dividends found for {ticker_symbol}. Skipping.")
except Exception as e:
print(f"Error updating last_dividend for {ticker_symbol}: {e}")
print("Last dividend data has been successfully updated!")
하하하ㅏ 후...
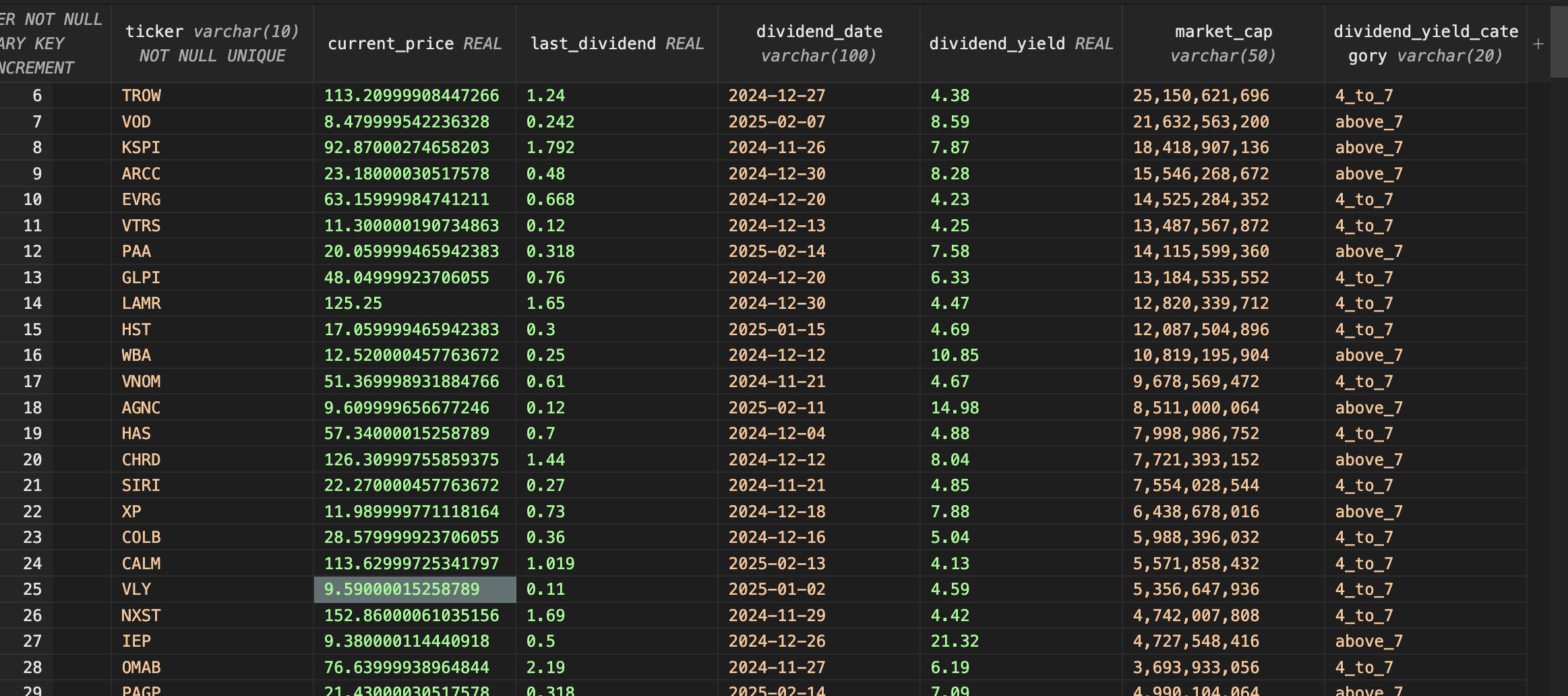
잘 나왔다 다행히도 ....
코드가 처음부터 잘 돌아가면 .... 이 고생을 하지 않아도 되는데 진짜 ...
내 로직이 잘 못된 건지 ... 무료 라이브러리의 한계인건지 모르겠지만 아무튼 ... 해냈음요..
그리고 이 db를 만들어내기까지 글에는 못 썼지만 ... 많은 시행착오가 있어서 (멍청이슈)
힘들고 때려칠까를 n번 정도 고민했지만 ... 그래도 !!! .... 하 만들어냈다.
근데 음 사실 이 코드의 결과물이 정확하냐..! 라는 물음엔 쉽게 yes라고 답할 수 없을 거 같다
왜냐하면
1. 야후 파이낸스에서 제공하지 않는 데이터도 많았고
2. 데이터를 뽑아내는 과정에서 마주하는 오류들이 내가 해결할 수 없는 것들이었다.
3. 그리고 무료 api이다 보니 누락된 데이터가 있을 수도....
그래서 야후 파이낸스에서 데이터를 뽑을 수 있는 건 최대한 많이 했는데 ..
내가 빠트린 부분이 있을 수도 있고 또 무료 api의 한계점은 반드시 있고...
그래서 이 데이터의 정확도는 80%~90%밖에 안 된다고 생각한다 .. 응응...
근데 또 로직을 뒤엎어서 짜자니 난 사실 자신이 없다 ...ㅎ ㅎㅎ...
일단 이대로 가고 .. 나중에 피드백을 받으면서 고치는 게 더 좋겠다는 생각을 했다!
자!! 로직을 대폭 수정한 후에, DB에 데이터 수집도 완료했으니,
이걸 view에서 불러내어 사이트로 보여주는 과정을 해보자!
물론 다음글에서~~
'프로젝트' 카테고리의 다른 글
| 나만의 배당주 사이트 만들기) 2-8. cron.py , view.py 작성하기, 디테일 잡기(숫자는 소수점 2번째 자리까지, 큰 숫자는 쉼표 넣어서, 페이지네이션 등) (2) | 2025.01.24 |
|---|---|
| 나만의 배당주 사이트 만들기) 2-6. 개발 단계 - 티커리스트 db에 저장해서 불러오기, 해결하지 못한 트러블슈팅 (0) | 2025.01.22 |
| 나만의 배당주 사이트 만들기) 2-5. 개발 단계 - 주식별 동적인 페이지 만들기, (시총, 주가내역, 배당 내역 등) (0) | 2025.01.21 |
| 나만의 배당주 사이트 만들기) 3. 디자인 - 잠깐 쉬어가자! 그런김에 디자인~! (0) | 2025.01.20 |
| 나만의 배당주 사이트 만들기) 2-4. 개발 단계 - 사이트 로딩 속도 줄이기 (0) | 2025.01.17 |